
Summary
In this article I will discuss the advantages of using Kafka as it relates to a very common integration pattern – Realtime messaging to batch feeds. You’re building systems that process live feeds, APIs, and user experiences that require immediate gratification. You also need to interact with legacy systems that can only support a nightly or hourly batch update process. How does one mediate between those 2 interaction models? The realtime to batch pattern pattern answers this question.
Whether your application architecture uses direct RESTful API calls, or uses event notifications using JMS, Kafka can provide some unique advantages when addressing this challenge.
The Traditional Realtime to Batch-Feed Pattern
For many years it seemed that every project we have been involved in requires integration with some backend component that only knows how to interact using an import and export of batches of data using a formatted file rather than a direct API. In the past couple of years, Java EE 7, JSR 352 and JMS 2.0 have arrived to support a batch processing solution that is much like what I am about to describe. However we have found that many clients these days aren’t willing to sign up for supporting the full Java EE stack, but rather want to keep dependency on vendors and frameworks to a minimum, code everything up themselves and keep everything out in the open. Also, the pattern described below will work against older versions of Java EE and JMS.
The solution we have implemented many times, illustrated in Figure 1, is to write a custom data collector that wiretaps each JMS message or RESTful service request as it arrives and write its contents out to intermediary staging tables or files. At regular intervals, as specified by a scheduler, extract all records from the staging tables that have arrived since the last extraction process and write them out to a specially formatted file to a specified location. A file polling mechanism associated with the target system notices that the new file has arrived, and imports it. Then clean up and repeat at regular intervals as dictated by the scheduler.
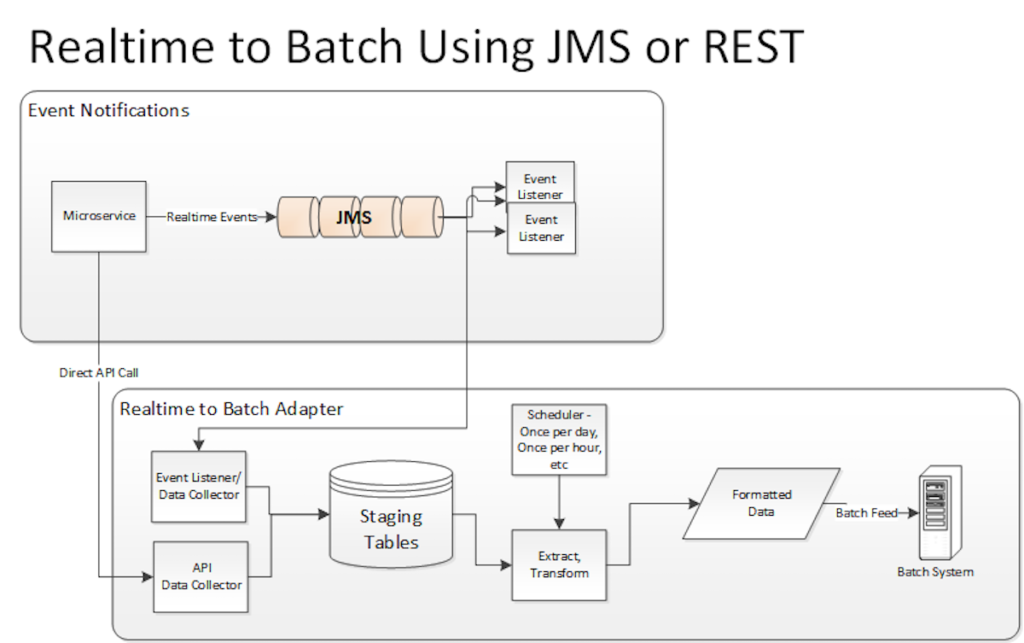
Figure 1: Realtime to batch conversion process that is fed by JMS 1.x or RESTful service calls
This seems simple enough, it takes work to build and maintain a separate database solely for the purpose of providing a temporary holding place for realtime data being collected for a nightly batch job. You could forgo the use of a database and write directly to a text file but as you scale up and have multiple writers you could have contention due to concurrency issues. What if there is an error writing to the file system? What is the retry or failover mechanism? What if there are new messages arriving while you are in the process of extracting the current snapshot? If using a 100% file based solution, you need to get clever with rotating file names and keeping track of the file being processed vs another file to put the ones that arrive while processing the current one. Or, if using the database solution, you need to track all rows with a status flag of what has been processed vs what’s currently being processed vs ones that arrive while you’re processing.
None of these problems are intractable, but there is an easier way to do it using Kafka. Before we explain the variation of the pattern using Kafka, we must first briefly explain some of the important subtle differences in message delivery using JMS vs using Kafka.
Kafka vs JMS
Kafka’s API and behavioral rules for how message receivers process messages are a bit different from how it is done using a more “traditional” JMS based message system. Initially I thought the Kafka API was a bit odd, having had JMS on the brain for so many years. However, once I got used to it I realized how powerful and flexible it could be, particularly when applied to this pattern.
While this will not be an exhaustive list of the nuances between JMS and Kafka, we will focus on the parts that affect the realtime to batch-feed pattern. The core of the difference between the two styles of messaging providers is this: JMS 1.x expects to deliver messages (events) to a message receiver (event listener) one message at a time in a FIFO fashion, While Kafka allows message receivers to process arriving messages as though they have their own message cursor offset into a continuous stream of inbound messages (Figure 2).

Figure 2: One-by-one JMS 1.x message delivery vs. Kafka message stream offsets
Using JMS, once a message is delivered and successfully processed, then it is gone, exposing the next message in line ready to be processed. Messages that may or may not be persistent, sent using a publish/subscribe Topic, may be delivered in a one-to-many fashion, with each receiver getting a copy of the message. The receiver will get a copy of the message if it is up and running and capable of receiving the message, otherwise the message may be discarded. Alternatively, messages delivered using a message Queue may be doled out to multiple receivers, but this is mostly for the purpose of load-balancing and failover; each message is processed by one and only one of the receivers. Most JMS providers provide several variations on these two delivery models, but the purposes of today’s discussion we will try to keep it simple as possible to focus on the integration pattern.
Kafka on the other hand, allows the message receiver to view the arriving messages as a continuous stream of messages, which can stay in the shared message stream indefinitely. Each message receiver can receive and process messages at its own pace. A message stream in Kafka has characteristics of both a Topic and a Queue. A Kafka message stream behaves like a pub/sub topic in that you can have one publisher and as many subscribers as needed, all of whom will get their own copy of each message. It also behaves like a queue in that message ordering is maintained, and messages are always persistent. One could argue that the differences are subtle, as that behavior could be closely imitated in JMS using durable subscriptions. However, as we explore the pattern we will see that the JMS behavior of deliver-process, deliver-process of each message gets in our way requires lots of extra work when mediating into a regularly scheduled batch stream, while Kafka makes it much simpler.
Realtime to batch using Kafka
Lets revisit the Realtime to batch pattern using Kafka. Because Kafka messages stay on disk for much longer periods of time, each message consumer can read and process messages at its own pace. Because a message consumer can keep track of its own cursor offset into the message stream, the consumer can read its messages form anywhere in the stream without having to always go to the head of the queue. This means that the consumer can go offline for a while, and upon activation by the scheduler, it can process all messages that arrived since the last time it did processing. Think of it as more of a pull model rather than a push (Figure 3).

Figure 3: Kafka message streams can persist for longer periods of time, obviating the need for a database or file for storing temporary data.
Since the message streams can persist for longer periods of time, they can stay around for a period of time that is longer than the window between batch runs. This obviates the need to have a database or a file as a temporary storage area. As events are emitted from the microservice, they are stored in the kafka message stream, and may stay there at least until the realtime to batch adapter can retrieve them.
In summary, due to its inherent unique qualities for how message streams are consumed, Kafka can be an attractive alternative to JMS when feeding realtime data into batch systems.